Colab setup

Model Interpretation using LIME for penguin dataset classifier
This notebook demonstrates the use of DIANNA with the RISE tabular method on the penguins dataset.
RISE is short for Randomized Input Sampling for Explanation of Black-box Models. It estimates each feature’s relevance to the model’s decision empirically by probing the model with randomly masked versions of the input text and obtaining the corresponding outputs. More details about this method can be found in the paper introducing RISE.
[1]:
running_in_colab = 'google.colab' in str(get_ipython())
if running_in_colab:
# install dianna
!python3 -m pip install dianna[notebooks]
0 - Import libraries
[2]:
import dianna
import numpy as np
import pandas as pd
import seaborn as sns
from sklearn.model_selection import train_test_split
from dianna.utils.onnx_runner import SimpleModelRunner
from dianna.utils.downloader import download
1 - Loading the data
Load penguins dataset.
[3]:
penguins = sns.load_dataset('penguins')
Prepare the data
[4]:
# Remove categorial columns and NaN values
penguins_filtered = penguins.drop(columns=['island', 'sex']).dropna()
# Get the species
species = penguins['species'].unique()
# Extract inputs and target
input_features = penguins_filtered.drop(columns=['species'])
target = pd.get_dummies(penguins_filtered['species'])
# Let's explore the features of the dataset
input_features
[4]:
| bill_length_mm | bill_depth_mm | flipper_length_mm | body_mass_g | |
|---|---|---|---|---|
| 0 | 39.1 | 18.7 | 181.0 | 3750.0 |
| 1 | 39.5 | 17.4 | 186.0 | 3800.0 |
| 2 | 40.3 | 18.0 | 195.0 | 3250.0 |
| 4 | 36.7 | 19.3 | 193.0 | 3450.0 |
| 5 | 39.3 | 20.6 | 190.0 | 3650.0 |
| ... | ... | ... | ... | ... |
| 338 | 47.2 | 13.7 | 214.0 | 4925.0 |
| 340 | 46.8 | 14.3 | 215.0 | 4850.0 |
| 341 | 50.4 | 15.7 | 222.0 | 5750.0 |
| 342 | 45.2 | 14.8 | 212.0 | 5200.0 |
| 343 | 49.9 | 16.1 | 213.0 | 5400.0 |
342 rows × 4 columns
The data-set currently has four features that were used to train the model: bill length, bill depth, flipper length, and body mass. These features were used to classify the different species.
Training, validation, and test data split.
[5]:
X_train, X_test, y_train, y_test = train_test_split(input_features, target, test_size=0.2,
random_state=0, shuffle=True, stratify=target)
Get an instance to explain.
[6]:
# get an instance from test data
data_instance = X_test.iloc[10].to_numpy()
2. Loading ONNX model
DIANNA supports ONNX models. Here we demonstrate the use of LIME explainer for tabular data with a pre-trained ONNX model, which is a MLP classifier for the penguins dataset.
The model is trained following this notebook: https://github.com/dianna-ai/dianna-exploration/blob/main/example_data/model_generation/penguin_species/generate_model.ipynb
[7]:
# load onnx model and check the prediction with it
model_path = download('penguin_model.onnx', 'model')
loaded_model = SimpleModelRunner(model_path)
predictions = loaded_model(data_instance.reshape(1,-1).astype(np.float32))
species[np.argmax(predictions)]
Downloading data from 'doi:10.5281/zenodo.10580742/penguin_model.onnx' to file '/home/elenar/.cache/dianna/penguin_model.onnx'.
[7]:
'Gentoo'
A runner function is created to prepare data for the ONNX inference session.
[8]:
import onnxruntime as ort
def run_model(data):
# get ONNX predictions
sess = ort.InferenceSession(model_path)
input_name = sess.get_inputs()[0].name
output_name = sess.get_outputs()[0].name
onnx_input = {input_name: data.astype(np.float32)}
pred_onnx = sess.run([output_name], onnx_input)[0]
return pred_onnx
3. Applying RISE with DIANNA
The simplest way to run DIANNA on image data is with dianna.explain_tabular.
DIANNA requires input in numpy format, so the input data is converted into a numpy array.
Note that the training data is also required for proper perturbation of the input data.
[9]:
explanation = dianna.explain_tabular(run_model, input_tabular=data_instance, method='rise',
mode ='classification', training_data = X_train.to_numpy(),
feature_names=input_features.columns, class_names=species)
Explaining: 100%|██████████████████████████████████████████████████████████████████████| 10/10 [00:00<00:00, 738.01it/s]
[10]:
run_model(data_instance[None,...])
[10]:
array([[1.3488360e-05, 3.1694275e-05, 9.9995482e-01]], dtype=float32)
4. Visualization
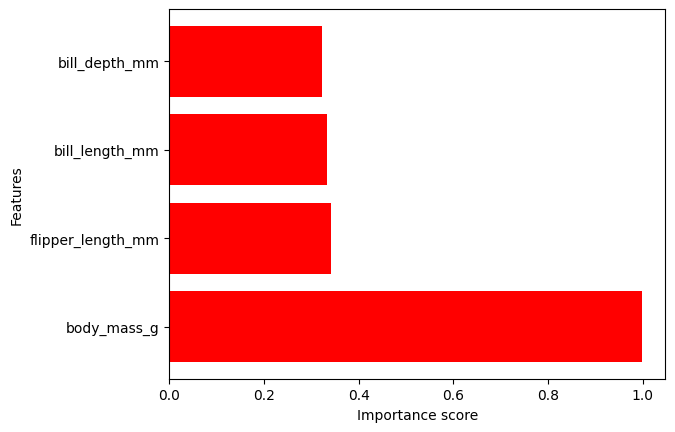
The output can be visualized with the DIANNA built-in visualization function. It shows the importance of each feature contributing to the prediction.
The prediction is “Gentoo”, so let’s visualize the feature importance scores for “Gentoo”.
It can be noticed that the body mass feature has the biggest weight in the prediction.
[11]:
from dianna.visualization import plot_tabular
_ = plot_tabular(explanation[np.argmax(predictions)], X_test.columns, num_features=10)
[12]:
explanation
[12]:
array([[6.3201445e-01, 6.6387820e-01, 6.6702765e-01, 8.4758140e-06],
[1.9935470e-02, 2.0091312e-02, 9.9996408e-04, 7.2206632e-05],
[3.3405048e-01, 3.2203084e-01, 3.4197244e-01, 9.9791914e-01]],
dtype=float32)
[ ]: